Airflow vs Databricks Jobs
Airflow vs Databricks Workflows🔗
Both Apache Airflow and Databricks Workflows are used to orchestrate jobs, but they solve different scopes of problems.
High-Level Difference🔗
| Aspect | Airflow | Databricks Workflows |
|---|---|---|
| Scope | Cross-platform orchestration | Databricks-centric orchestration |
| Primary use | Orchestrate many systems | Orchestrate Databricks jobs |
| Language | Python DAGs | UI + JSON + notebooks |
| Best at | Complex dependencies across tools | Spark / Databricks pipelines |
| Vendor lock-in | Low | High (Databricks only) |
Core Philosophy🔗
Airflow🔗
- Platform-agnostic orchestrator
- Controls Spark, dbt, Snowflake, APIs, ML, scripts
- DAGs live outside compute engines
- Ideal for enterprise-wide orchestration
Databricks Workflows🔗
- Native job orchestration inside Databricks
-
Tight integration with:
-
Notebooks
- Jobs
- Delta Live Tables
- Unity Catalog
- Ideal for lakehouse-only pipelines
Architecture Comparison🔗
Airflow-Centric🔗
Databricks Workflows-Centric🔗
Scheduling & Dependencies🔗
Airflow🔗
- Explicit task dependencies (
task_a >> task_b) -
Rich scheduling:
-
Cron
- Backfills
- Catchup
- SLA monitoring
- Cross-DAG dependencies supported
Databricks Workflows🔗
- Linear or DAG-like job tasks
- Simple schedules
- Limited cross-job dependency logic
- Best for straightforward pipelines
Failure Handling & Observability🔗
Airflow🔗
- Fine-grained retries per task
- Task-level logs
- Clear / rerun specific steps
- SLA alerts and callbacks
Databricks Workflows🔗
- Job-level monitoring
- Notebook logs
- Less granular retry logic
- Easier but less flexible
Development Experience🔗
Airflow🔗
- Code-first (Python)
- Version controlled
- More setup overhead
- Steeper learning curve
Databricks Workflows🔗
- UI-driven
- Fast to start
- Less boilerplate
- Easier for analytics teams
When to Use Which🔗
Use Airflow when:🔗
- You orchestrate multiple systems
- You need complex dependencies
- You want vendor-neutral orchestration
- You run enterprise-scale pipelines
Use Databricks Workflows when:🔗
- Everything runs in Databricks
- Pipelines are Spark-centric
- You want minimal orchestration overhead
- You rely heavily on DLT and notebooks
Common Enterprise Pattern (Best Practice)🔗
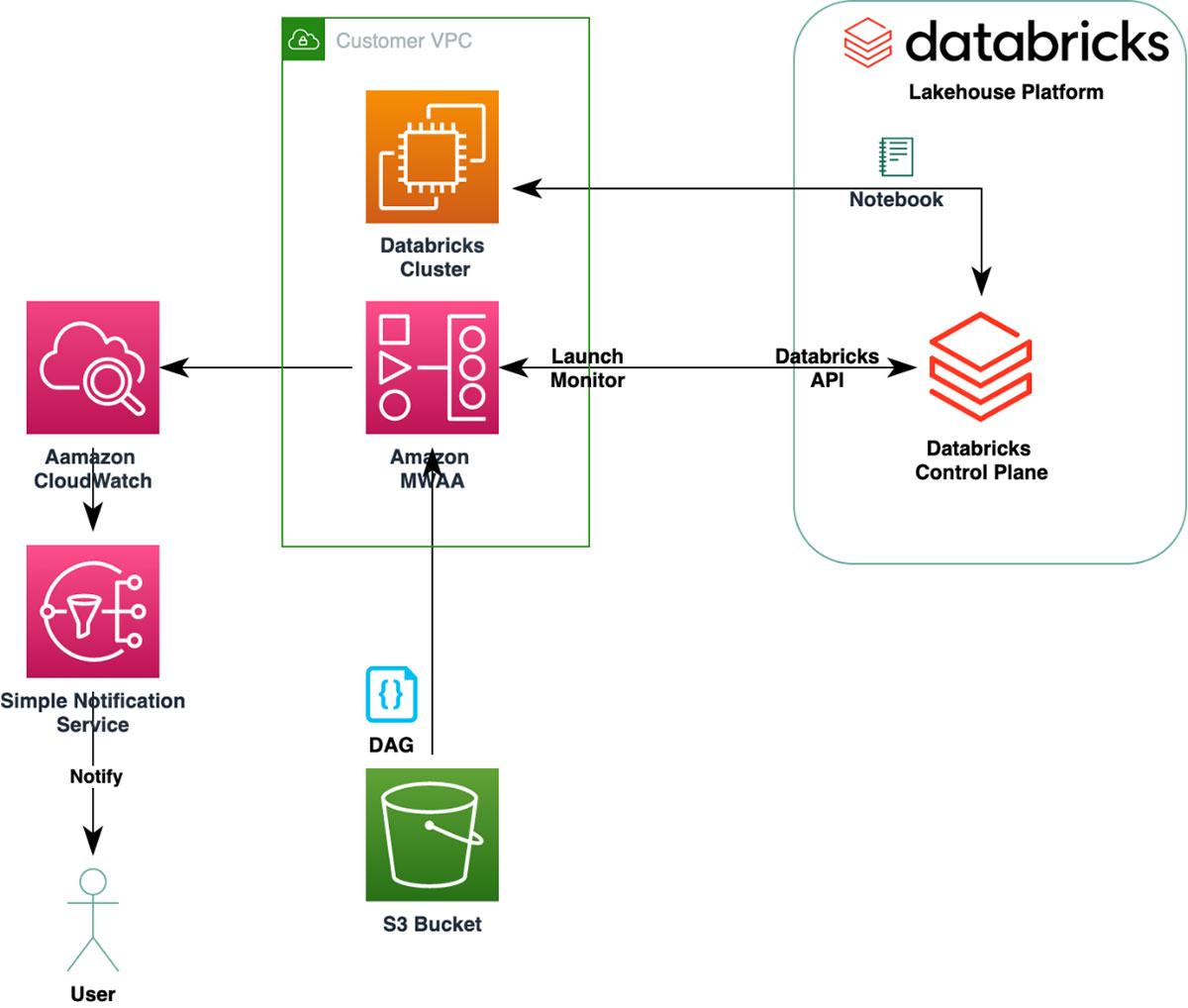
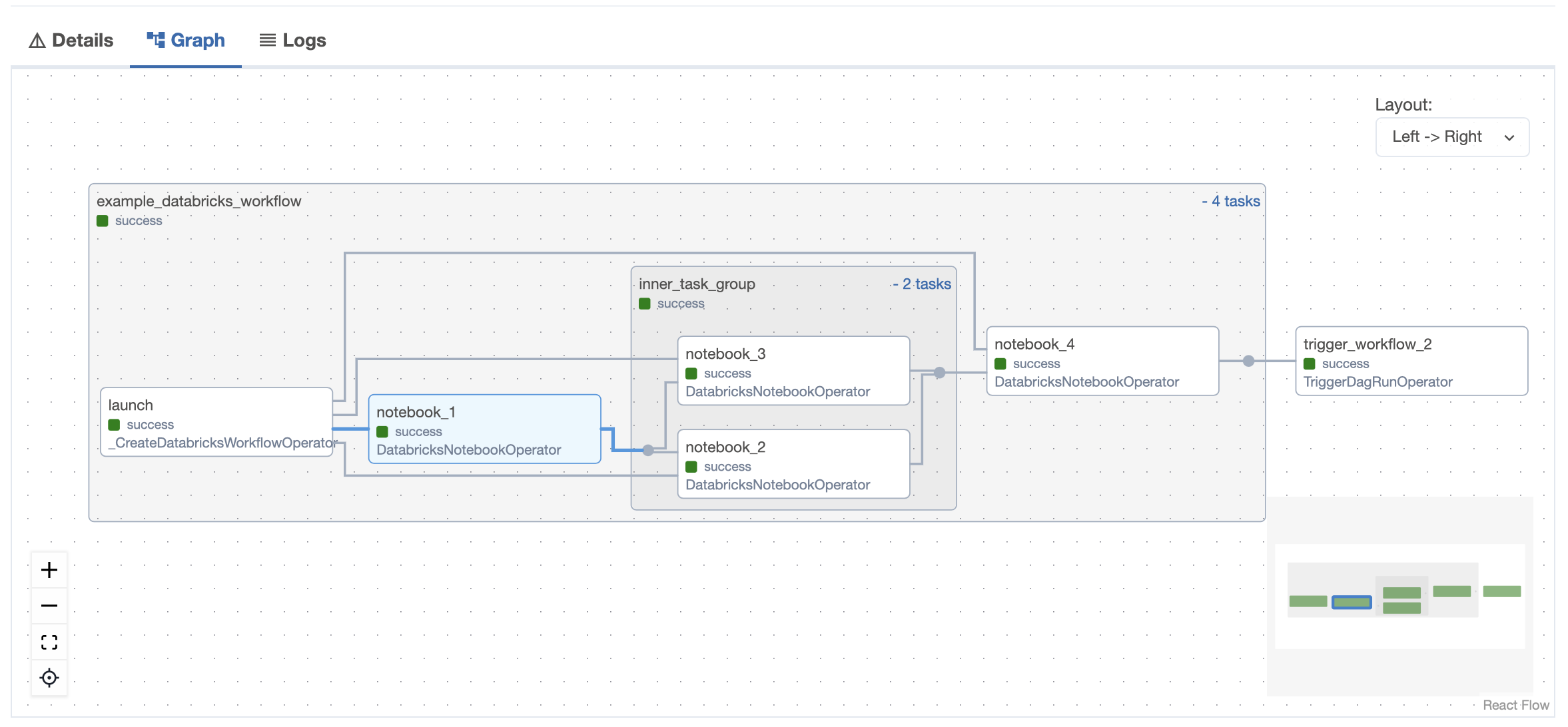
Airflow handles:
- Scheduling
- Cross-system dependencies
- Alerts
Databricks handles:
- Compute
- Transformations
- Lakehouse logic
Decision Cheat Sheet🔗
| Scenario | Recommendation |
|---|---|
| Company-wide orchestration | Airflow |
| Databricks-only platform | Databricks Workflows |
| Hybrid cloud stack | Airflow |
| Simple Spark pipelines | Databricks Workflows |
| Complex SLAs & dependencies | Airflow |
One-Line Summary🔗
Use Airflow as the enterprise orchestrator and Databricks Workflows as the execution engine for Spark-based pipelines.
Cost, Scaling, and Failure Trade-offs🔗

1) Cost Model🔗
Apache Airflow🔗
What you pay for
- Infrastructure (VMs / Kubernetes nodes)
- Metadata DB (Postgres / MySQL)
- Logging (S3, CloudWatch, GCS)
- Engineering time (maintenance)
Cost characteristics
- Scheduler and workers are always on
- Cost is mostly fixed
- Orchestrating 10 tasks vs 10,000 tasks does not multiply cost linearly
Hidden costs
- Upgrades
- Plugin/operator maintenance
- Scaling scheduler for large DAG counts
Typical monthly pattern
- Stable, predictable
- Good for heavy orchestration workloads
Databricks Workflows🔗
What you pay for
- DBUs for job clusters
- Cloud compute (per run)
- Storage and logs
Cost characteristics
- Pay per job execution
-
Scales linearly with:
-
Number of jobs
- Runtime
- Cluster size
Hidden costs
- Frequent small jobs become expensive
- Retries mean re-running full clusters
Typical monthly pattern
- Spiky
- Sensitive to retry storms and inefficient jobs
2) Scaling Behavior🔗
Airflow Scaling🔗
What scales
- Number of DAGs
- Number of tasks
- Number of parallel executions
Scaling limits
-
Scheduler becomes bottleneck at:
-
Tens of thousands of DAGs
- Millions of task instances/day
-
Requires tuning:
-
Scheduler heartbeat
- DAG parsing
- Executor choice
Good at
- Many lightweight orchestration steps
- Cross-team pipelines
- Enterprise-scale dependency graphs
Databricks Workflows Scaling🔗
What scales
- Spark compute
- Data volume
- Parallel job runs
Scaling limits
- Each job = separate cluster or task
- Job orchestration logic is limited
- UI becomes hard to manage at large job counts
Good at
- Heavy Spark workloads
- Data volume scaling
- CPU/memory intensive pipelines
3) Failure Handling & Blast Radius🔗
Airflow Failure Model🔗
Granularity
- Task-level failures
- Retry individual tasks
- Clear and rerun partial DAGs
Blast radius
- Small
- One failed task does not kill entire pipeline
Operational advantage
- Can fix downstream issues without reprocessing everything
- Ideal for long multi-step pipelines
Databricks Workflows Failure Model🔗
Granularity
- Often job or notebook-level
- Retry usually means rerunning large portions
Blast radius
- Large
- Cluster startup + job rerun costs incurred
Operational impact
- Costly retries
- Less control for partial recovery
4) Backfills and Reprocessing🔗
Airflow🔗
- Native support for backfills
- Re-run historical partitions cleanly
- Strong date-based semantics (
execution_date)
Best for:
- Regulatory backfills
- Finance and insurance recomputations
- Late-arriving data corrections
Databricks Workflows🔗
-
Backfills require:
-
Manual parameterization
- Custom logic
- No first-class historical orchestration model
Best for:
- Forward-only pipelines
- Idempotent batch jobs
5) Observability & Operations🔗
Airflow🔗
- DAG-level visibility
- Task timelines
- SLA misses
- Fine-grained logs
Operations-heavy but transparent.
Databricks Workflows🔗
- Strong Spark-level metrics
- Cluster metrics
- Less orchestration visibility
Compute-heavy but simpler operationally.
6) Real Enterprise Pattern (Cost-Optimal)🔗
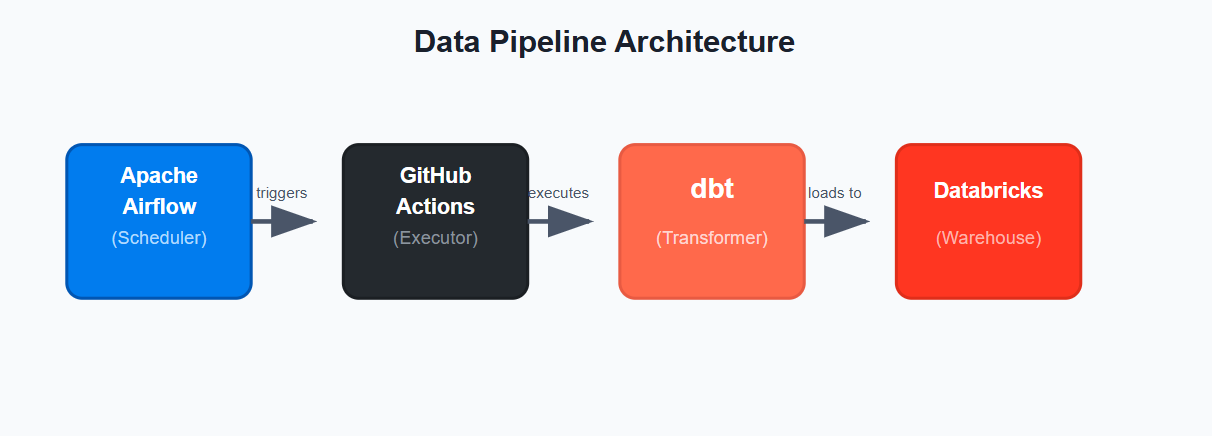
Airflow
├─ Lightweight checks
├─ Dependency orchestration
├─ SLA & alerts
↓
Databricks Workflows
├─ Heavy Spark transforms
├─ DLT pipelines
└─ Feature engineering
Why this works:
- Airflow absorbs orchestration complexity cheaply
- Databricks only runs when real compute is needed
- Failures are isolated and cheaper to recover
Decision Matrix🔗
| Requirement | Better Choice |
|---|---|
| Many pipelines, light logic | Airflow |
| Heavy Spark processing | Databricks Workflows |
| Complex retries & partial reruns | Airflow |
| Cost control at scale | Airflow |
| Simple Databricks-only stack | Databricks Workflows |
| Regulatory backfills | Airflow |
Final Takeaway🔗
- Airflow optimizes orchestration cost, control, and failure isolation
- Databricks Workflows optimizes compute scalability and execution simplicity
- Best practice is Airflow orchestrating Databricks, not replacing it